Deep learning is a type of artificial intelligence that uses neural networks to analyze data and solve complicated problems. To train these networks, we need optimizers like stochastic gradient descent (SGD) that help us find the minimum weights and biases at which the model loss is lowest. However, SGD has some issues when it comes to non-convex cost function graphs, and this is why we use SGD with Momentum as an optimizer.
Reasons why SGD does not work perfectly
The three main reasons why SGD does not work well with non-convex cost function graphs are:
- Local Minima: When we randomly start at some point, we can end up at a local minimum and not reach the global minimum.
- Saddle Point: A saddle point is a point where the slope is changing very gradually and the speed of changing is slow. It is difficult to traverse when the radius is large and is generally high in non-convex optimization.
- High Curvature: The larger the radius the lower the curvature and vice versa. It is difficult to traverse the high curvature regions.
What is SGD with Momentum?
SGD with Momentum is one of the optimizers that is used to improve the performance of neural networks. The main concept behind SGD with Momentum is the idea that if all previous points are pointing in the same direction, then the confidence of the next point is increased, and it will go in that direction very fast. We can think of this like a ball sliding down a slope; as it goes, its speed increases over time.
How does SGD with Momentum work?
SGD with Momentum uses the concept of Exponentially Weighted Moving Average (EWMA), a technique that helps us find the trend in time series data. The formula for EWMA is:
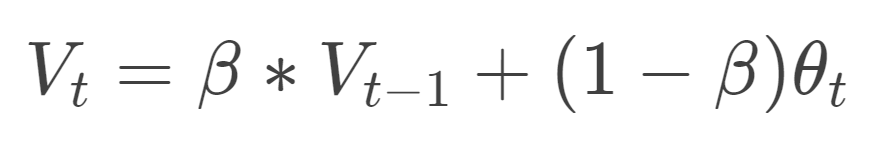
The beta value in the formula represents the weight assigned to past values of the gradient. The higher the beta value, the more it tries to get an average of more past data, and vice versa. For example, if the value of beta is 0.98, then we calculate the average using the past 50 readings.
In SGD with Momentum, we use the same concept of EWMA, but we introduce the term velocity (v), which denotes the change in the gradient to reach global minima. The formula for the change in weights is:
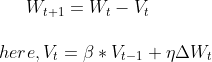
The beta part of the velocity formula is useful to compute the confidence or the past velocity for calculating Vt. We use the history of velocity to calculate momentum, which provides acceleration to the formula.
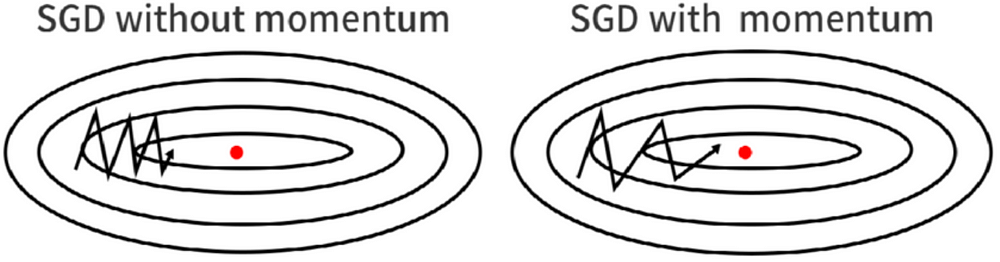
We have to consider two cases:
- Beta equals zero: In this case, the weight updating works as a stochastic gradient descent. Beta here is called a decaying factor because it defines the speed of past velocity.
- Beta equals one: In this case, there will be no decay, and it involves dynamic equilibrium, which is not desired. We generally use the value of beta like 0.9, 0.99, or 0.5 only.
Advantages of SGD with Momentum
SGD with Momentum has two significant advantages:
- Momentum is faster than stochastic gradient descent, and the training will be faster than SGD.
- Local minima can be escaped, and global minima can be reached due to the momentum involved.
Although momentum itself can be a problem sometimes because of its high momentum after reaching the global minima, it still fluctuates and takes some time to get stable at the global minima. This kind of behavior leads to time consumption, making SGD with Momentum slower than other optimization methods out there but still faster than SGD.
