Clustering is a technique that helps us group similar items together.
Imagine you have a bag of colorful candies, and you want to organize them by color.
You would naturally group the red candies together, the blue candies together, and so on. Clustering algorithms do something similar, but with data points instead of candies.
One such algorithm is called "Mean Shift Clustering," and in this article, we'll explore how it works in a simple and intuitive way.
Mean shift
Mean shift is based on the idea of KDE, but what makes it different is that using the bandwidth parameter.
We can make the points climb uphill to the nearest peak on the KDE surface.
So, iteratively shifting each point to climb uphill to the peak.
The bandwidth parameter used to make the KDE surface varies on the different sizes.
For example, we have a tall skinny kernel which means a small kernel bandwidth and in a case where the size of the kernel is short and fat, which means a large kernel bandwidth.
A small kernel bandwidth makes the KDE surface hold the peak for every data point more formally, saying each point has its cluster; on the other hand, large kernel bandwidth results in fewer kernels or fewer clusters.
What is Mean Shift Clustering?
Mean Shift Clustering is a machine learning algorithm that helps us find clusters or groups in data.
It's like a magnet that attracts data points towards the center of a cluster.
The algorithm starts with a random point and iteratively shifts it towards the densest region of data points until it converges to the center of a cluster. This process is repeated for multiple starting points until all clusters are identified.
A Non-Technical Example
To understand Mean Shift Clustering, let's consider a non-technical example. Imagine you're in a dark room with a flashlight, and your goal is to find groups of people standing together.
You start by shining the flashlight at a random spot and observe the people around that spot.
You then move the flashlight towards the area with the most people. You keep doing this until you reach the center of the group, where people are most densely packed.
You've now found one cluster!
You repeat this process for other random spots until you've found all the groups in the room.
That's how Mean Shift Clustering works!
Technical Explanation
Now, let's dive into the technical details of Mean Shift Clustering. The algorithm involves the following steps:
- Initialization: Choose a random data point as the initial "seed" point.
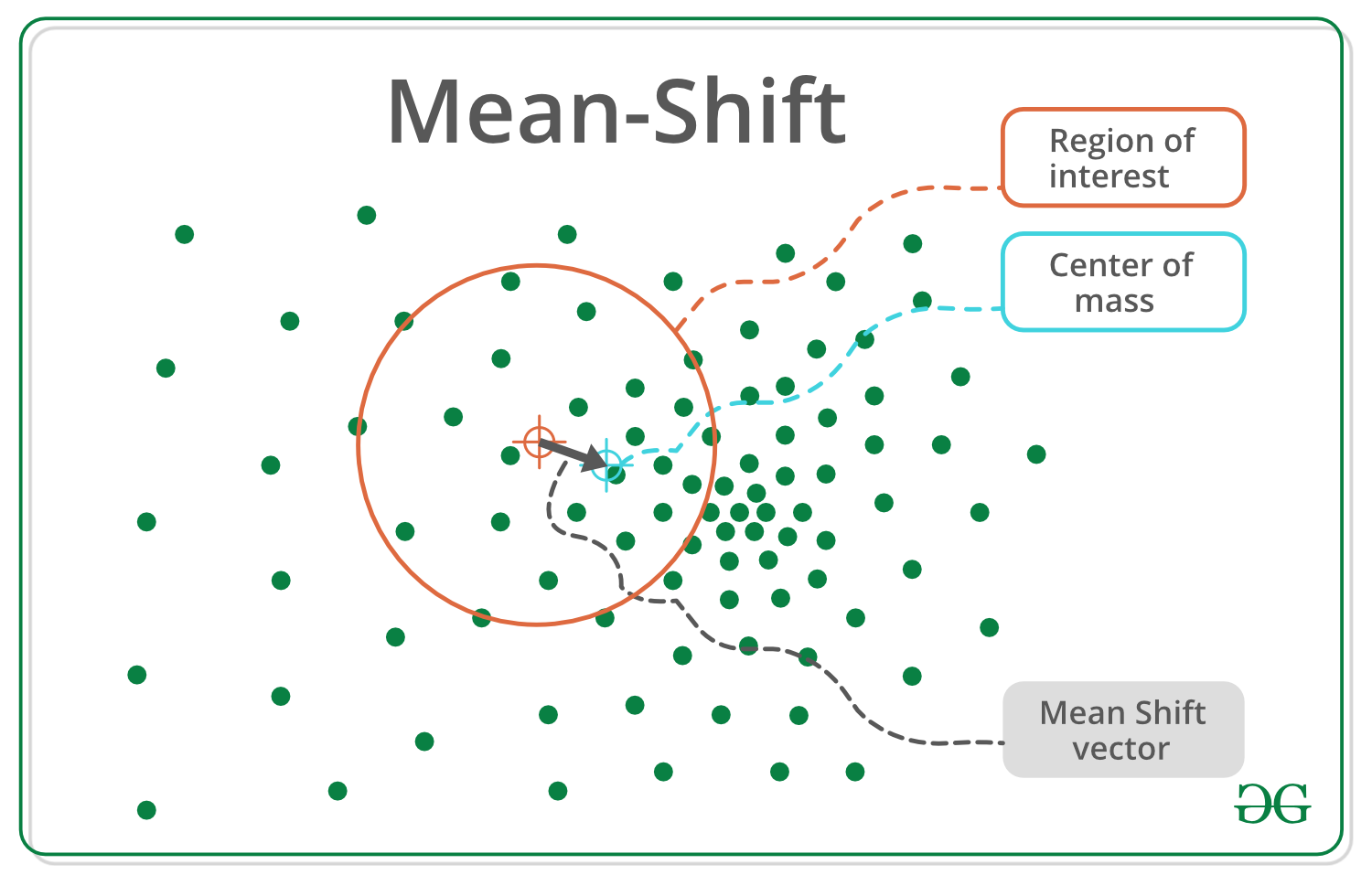
- Mean Shift Iteration: Calculate the mean (average) of the data points within a certain radius (called the "bandwidth") around the seed point. Shift the seed point to the calculated mean.
- Convergence: Repeat the Mean Shift Iteration until the seed point no longer moves significantly. This indicates that the seed point has converged to the center of a cluster.
- Repeat: Repeat steps 1-3 for other seed points until all clusters are identified.
The bandwidth parameter controls the size of the search window around the seed point. A larger bandwidth results in larger clusters, while a smaller bandwidth may result in more clusters.
How Does Mean Shift Clustering Work?
The core idea of Mean Shift clustering is to move each data point toward the densest region within its neighborhood. The algorithm does this by calculating the average (mean) location of nearby data points and shifting the original point toward that average. This process is repeated for all data points until they settle into stable positions, forming the centers of the clusters.
Here's a step-by-step breakdown of the Mean Shift clustering process:
- Start with Data Points: Begin with a set of data points, each treated as an initial cluster center.
- Iterate and Shift: For each data point, find nearby points within a certain distance (the "kernel radius"). Calculate the average location of these nearby points and shift the original point toward this average.
- Check for Convergence: Repeat the shifting process until the data points no longer move significantly. These stable points are the final cluster centers.
- Assign Clusters: Group data points based on their proximity to the final cluster centers.
The choice of kernel radius is important, as it determines the size of the neighborhood around each data point. A larger radius may result in fewer, larger clusters, while a smaller radius may lead to more, smaller clusters.
Real-World Applications
Mean Shift clustering is versatile and has a variety of practical applications, including:
- Image Processing: Mean Shift can segment images into regions with similar colors or features, enhancing image analysis and computer vision tasks.
- Video Tracking: The algorithm can track moving objects in video streams by continuously updating cluster centers based on object movement.
- Bioinformatics: Mean Shift can analyze biological data, such as gene expression patterns, to identify meaningful clusters and patterns.
Advantages and Considerations
Mean Shift clustering offers several benefits:
- Flexibility: It can handle clusters of different shapes and sizes, making it suitable for diverse datasets.
- Automatic Cluster Detection: The algorithm determines the number of clusters based on data density, eliminating the need to specify the number of clusters in advance.
However, there are some considerations:
- Kernel Radius Selection: The choice of kernel radius affects clustering results. An inappropriate radius may lead to over- or under-clustering.
- Computation Time: Mean Shift can be slower for large datasets due to its iterative nature.
Applications of Mean Shift Clustering
Mean Shift Clustering has a wide range of applications, including:
- Image Segmentation: Mean Shift Clustering can be used to segment images into regions of similar colors or textures, which is useful for computer vision tasks.
- Object Tracking: The algorithm can track moving objects in videos by continuously updating the cluster centers.
- Anomaly Detection: Mean Shift Clustering can identify outliers or anomalies in data by detecting data points that do not belong to any cluster.
Advantages and Limitations
Mean Shift Clustering has several advantages:
- No Assumption of Cluster Shape: Unlike some other clustering algorithms, Mean Shift Clustering does not assume that clusters have a specific shape (e.g., spherical).
- Automatic Cluster Detection: The algorithm automatically determines the number of clusters based on the data distribution.
However, there are some limitations:
- Choice of Bandwidth: The choice of bandwidth can significantly affect the results. A poor choice may lead to over-clustering or under-clustering.
- Computationally Intensive: The algorithm can be slow for large datasets due to the iterative nature of the mean shift process.
